5가지 데이터 사이언스 워크플로우 속도 향상 방법

데이터 사이언스는 정말 멋집니다. 하지만 코드가 실행되는 것을 오래 기다리는 것은 전혀 멋지지 않죠. 느린 데이터 로딩, 비효율적인 루프, 밤새 진행되는 하이퍼파라미터 튜닝 등의 병목 현상은 생산성을 저하시킵니다. 다행히도 이를 해결할 방법이 있습니다. 워크플로우를 더 빠르고, 원활하고, 덜 답답하게 만들기 위한 다섯 가지 확실한 기술에 대해 알아보겠습니다.
사전 지식
시작하기 전에, 다음 내용에 익숙해야 합니다:
- Python (아직도 for 루프로 어려움을 겪고 있다면 다른 대화가 필요합니다)
- Jupyter Notebook 또는 IDE (메모장에서 파이썬을 작성하지 않는 한...)
- 머신러닝 파이프라인 (전처리, 특성 엔지니어링, 모델 평가가 무엇인지 알아야 합니다)
- 병렬 컴퓨팅 및 멀티스레딩 (기본 개념 - 멀티프로세싱, 스레딩, 비동기 실행)
- Git 및 버전 관리 (진행 상황을 잃는 것은 특별한 고통입니다)
- GPU 가속화 (CuPy를 들어봤나요? 스테로이드를 맞은 NumPy와 같습니다)
데이터 사이언스는 무언가 이상한 일이 발생하여 진행이 중단될 때까지 새로운 아이디어, 실험, 갑작스러운 깨달음의 순간으로 가득 찬 흥미로운 여정과 같습니다. 데이터셋이 달팽이처럼 느리게 로드되거나 모델 훈련이 영원히 끝나지 않는 것을 본 적이 있다면 정확히 무슨 말인지 알 것입니다.
작업 속도를 높이는 것은 지름길을 찾는 것이 아니라 더 똑똑하게 일하는 것입니다. 최고의 데이터 과학자들은 단지 훌륭한 모델을 구축하는 것뿐만 아니라 프로세스의 모든 단계가 효율적으로 실행되도록 하여 진행 표시줄이 움직이기를 기다리는 대신 문제 해결에 시간을 집중할 수 있도록 합니다.
이 가이드는 워크플로우를 가속화하고 개선하는 다섯 가지 방법을 제공합니다. 지저분한 데이터와 씨름하든, 모델을 미세 조정하든, 지루한 작업을 자동화하든 간에 이러한 기술은 낭비되는 시간을 줄이고 정말 중요한 것에 집중하는 데 도움이 될 것입니다.
1. 데이터 로딩 및 전처리 최적화
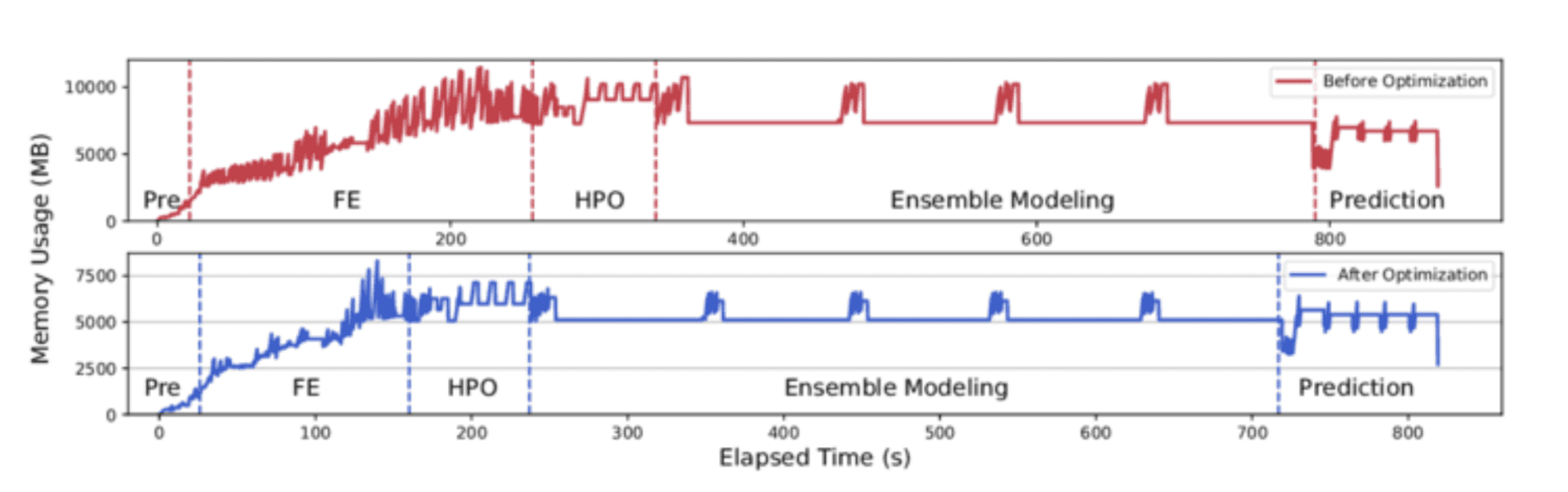
문제점
대용량 데이터셋은 큰 골칫거리입니다. 느린 로딩, 비효율적인 데이터 타입, 메모리 과다 사용은 간단한 작업도 지루하게 만듭니다.
해결책
pandas.read_csv()를 제대로 사용하세요. 데이터 타입을 설정하고, 데이터를 청크 단위로 처리하고, 불필요한 열을 로드하지 마세요.
python
import pandas as pd
메모리 절약을 위해 특정 데이터 타입 사용
dtypes = {"column1": "int32", "column2": "float32"}
대용량 파일을 청크 단위로 읽기
chunksize = 10000
df_list = []
for chunk in pd.readcsv("largefile.csv", dtype=dtypes, chunksize=chunksize):
df_list.append(chunk)
df = pd.concat(df_list)
✓ 메모리 과다 사용을 방지하기 위해 dtype을 설정하세요.
✗ 고려 없이 read_csv()를 사용하지 마세요 - 크래시를 원한다면 모를까요.
2. 벡터화 연산 및 최적화된 라이브러리 활용
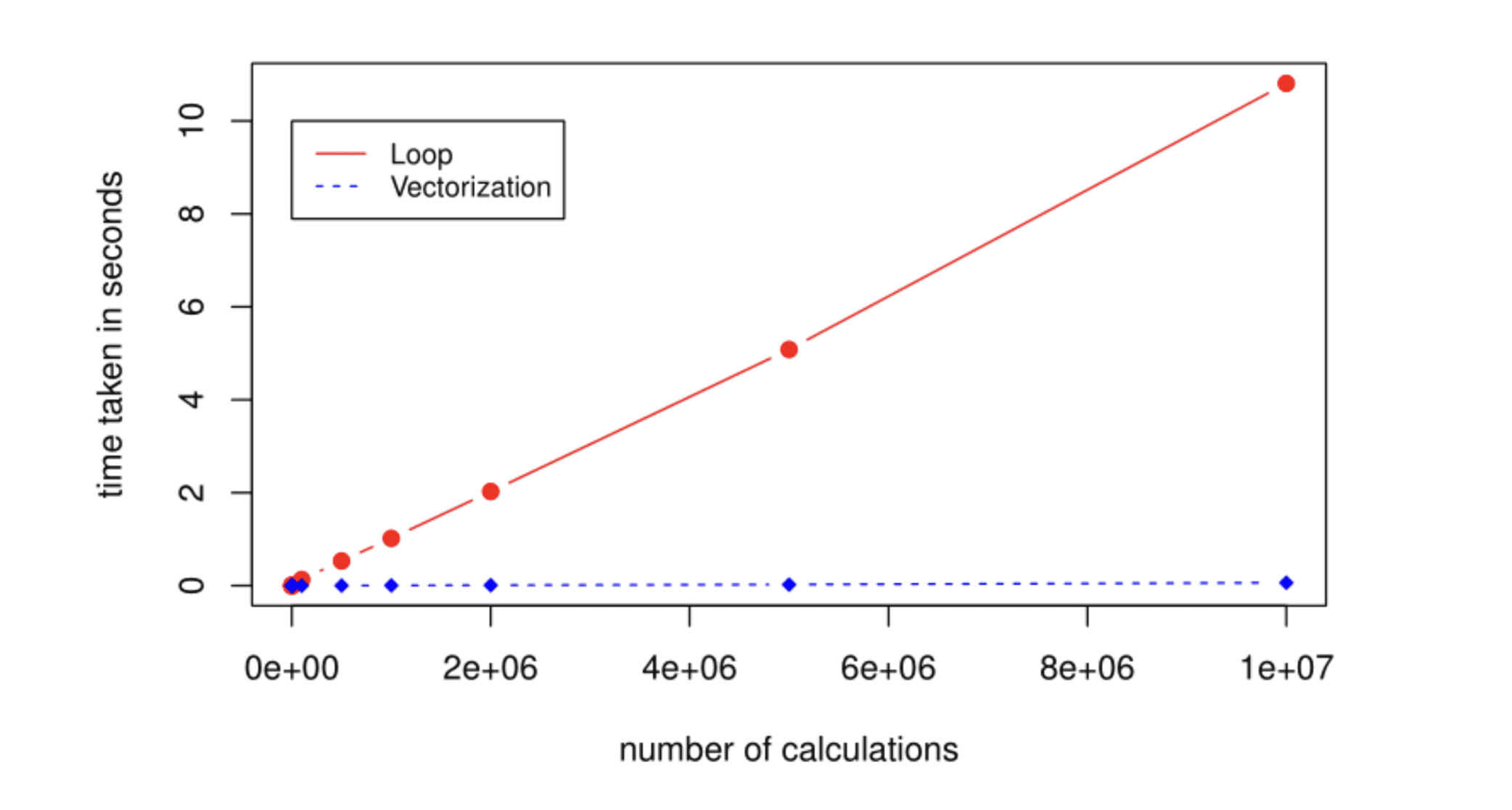
문제점
파이썬 루프는 매우 느립니다.
해결책
루프 대신 NumPy를 사용하세요.
python
import numpy as np
비효율적인 방법
squared = [i2 for i in range(1000000)]
효율적인 방법
squared = np.arange(1000000) 2
✓ 속도 향상을 위해 NumPy와 Pandas를 사용하세요.
✗ Pandas에서 행을 반복하지 마세요. 절대로.
3. 병렬 및 분산 컴퓨팅 구현
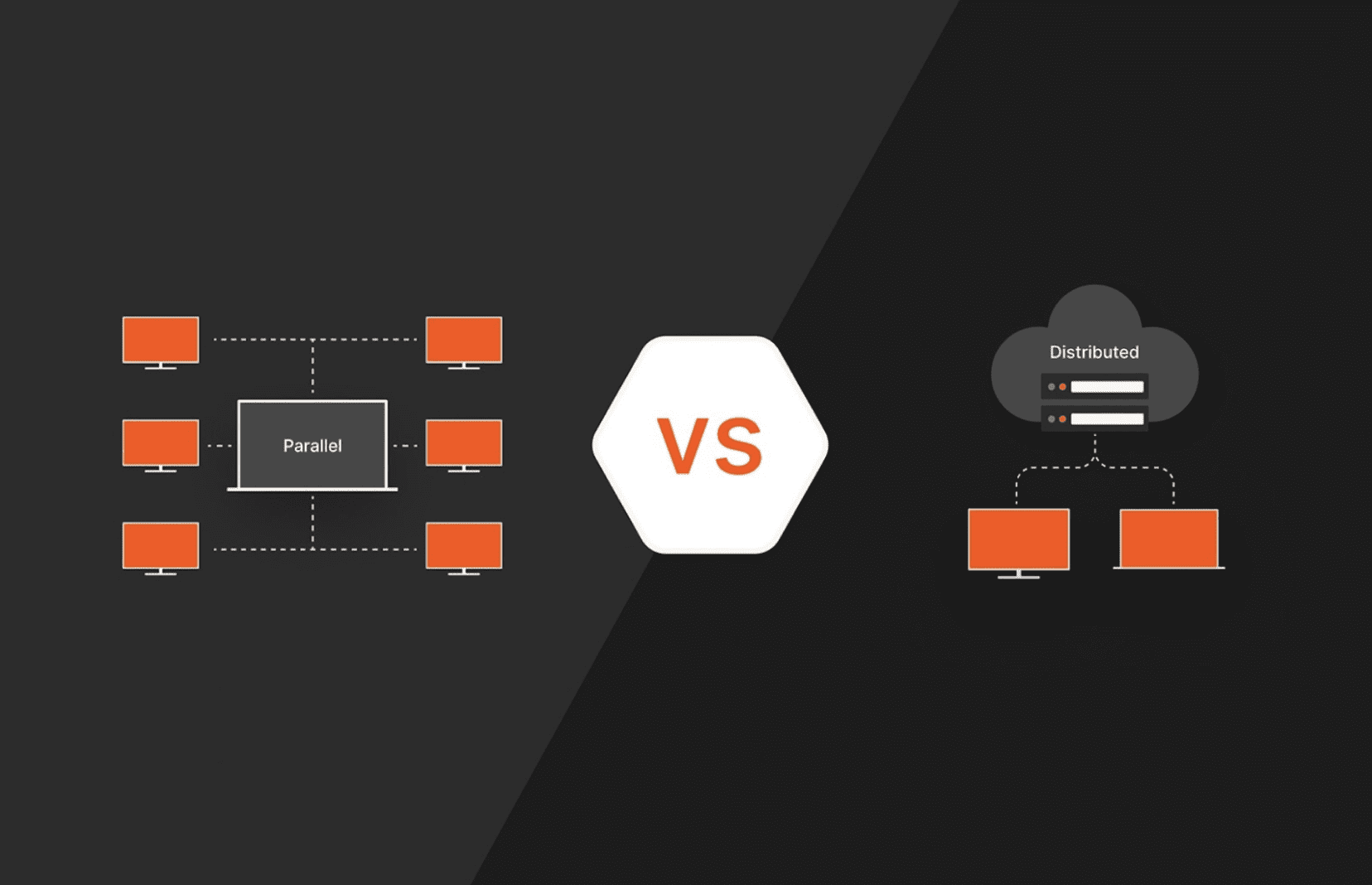
문제점
컴퓨터가 열심히 일하고 있지만 하나의 코어만 사용하고 있습니다.
해결책
코드를 병렬화하기 위해 joblib을 사용하세요.
python
from joblib import Parallel, delayed
import time
def square(n):
time.sleep(1)
return n * n
numbers = range(10)
results = Parallel(n_jobs=4)(delayed(square)(n) for n in numbers)
print(results)
✓ 데이터셋이 메모리에 비해 너무 크다면 Dask를 사용하세요.
✗ 너무 많은 프로세스를 생성하지 마세요. 속도 대신 혼란을 만들게 됩니다.
4. 효율적인 모델 선택 및 하이퍼파라미터 튜닝 사용
문제점
그리드 서치는 영원히 걸립니다.
해결책
무차별 대입 그리드 서치 대신 RandomizedSearchCV를 사용하세요.
python
from sklearn.model_selection import RandomizedSearchCV
from sklearn.ensemble import RandomForestClassifier
paramdist = {"nestimators": [10, 50, 100, 200], "max_depth": [None, 10, 20, 30]}
model = RandomForestClassifier()
randomsearch = RandomizedSearchCV(model, paramdistributions=paramdist, niter=10, cv=5)
randomsearch.fit(Xtrain, y_train)
✓ 베이지안 최적화(Optuna)를 시도해보세요.
✗ 무제한 시간이 없다면 무작정 GridSearchCV를 사용하지 마세요.
5. 파이프라인으로 반복 작업 자동화
문제점
수동으로 전처리 단계를 반복하는 것은 오류가 발생하기 쉽고 지루합니다.
해결책
scikit-learn 파이프라인을 사용하세요.
python
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
pipeline = Pipeline([
('scaler', StandardScaler()),
('classifier', RandomForestClassifier(n_estimators=100))
])
pipeline.fit(Xtrain, ytrain)
✓ 전처리를 모듈화하세요.
✗ 파이프라인을 과도하게 복잡하게 만들지 마세요 - 읽기 쉽게 유지하세요.
보너스: GPU 가속으로 성능 향상
문제점
좋은 라이브러리를 사용해도 CPU는 대용량 데이터셋이나 복잡한 계산을 처리할 때 매우 느릴 수 있습니다.
해결책
CuPy를 시도해보세요 - NVIDIA GPU용 NumPy와 같지만 훨씬 빠릅니다. 가장 좋은 점은 NumPy에서 CuPy로의 전환이 매우 쉽다는 것입니다.
python
import numpy as np
import cupy as cp
import time
size = (10000, 10000)
cpu_matrix = np.random.rand(*size)
gpu_matrix = cp.random.rand(*size)
CPU 계산 (NumPy)
start = time.time()
cpuresult = np.dot(cpumatrix, cpu_matrix)
end = time.time()
print(f"CPU time: {end - start:.4f} seconds")
GPU 계산 (CuPy)
start = time.time()
gpuresult = cp.dot(gpumatrix, gpu_matrix)
cp.cuda.Device(0).synchronize()
end = time.time()
print(f"GPU time: {end - start:.4f} seconds")
✓ 대규모 행렬 연산에는 CuPy를 사용하세요.
✗ 작은 데이터셋에는 사용하지 마세요 - GPU 전송 오버헤드가 속도 이점을 상쇄합니다.
알고 계셨나요?
💡 Pandas + Modin을 사용하면 여러 CPU 코어를 사용할 수 있습니다. 자전거에서 스포츠카로 바꾸는 것과 같습니다.
흔한 실수
✗ 벡터화된 연산 대신 루프를 과도하게 사용하는 것.
✗ 메모리 효율적인 데이터 타입을 무시하는 것.
결론
워크플로우를 최적화하는 것은 더 열심히 일하는 것이 아니라 더 똑똑하게 일하는 것입니다. 느린 프로세스를 제거하고, 적절한 도구를 사용하고, 반복적인 작업을 자동화하여 시간을 절약하세요. 작은 조정으로도 몇 시간을 절약할 수 있습니다. 항상 개선점을 찾고, 최적화를 계속하고, 작업이 수월해지도록 만드세요. 오늘부터 이러한 방법을 적용하고 생산성이 향상되는 것을 지켜보세요.