AI로 데이터 분석을 배우는 방법 (2025년 가이드)

데이터 분석의 패러다임이 변화했습니다. 이제는 데이터 분석가가 되기 위해 파이썬, SQL, 엑셀과 같은 도구만 알아서는 충분하지 않습니다.
테크 기업의 데이터 전문가로서, 저는 AI가 모든 직원의 업무 흐름에 통합되는 것을 직접 경험하고 있습니다. 이제 전체 데이터베이스에 접근하여 분석할 수 있고, 데이터 분석 프로젝트, 머신러닝 모델, 웹 애플리케이션을 몇 분 만에 구축할 수 있는 AI 도구들이 넘쳐납니다.
데이터 전문가를 꿈꾸는 사람이라면 이러한 AI 도구를 활용해야 합니다. 그렇지 않으면 곧 AI를 활용해 업무 효율을 높이는 다른 데이터 분석가들에게 뒤처질 수 있습니다.
이 글에서는 경쟁에서 앞서 나가고 데이터 분석 워크플로우를 10배 향상시킬 수 있는 AI 도구들을 소개하겠습니다.
이러한 도구들을 사용하면 다음과 같은 일을 할 수 있습니다:
- 데이터 분석가로 취업하기 위한 창의적인 포트폴리오 프로젝트 구축 및 배포
- 일반 영어로 엔드투엔드 데이터 분석 애플리케이션 생성
또한, 이 글은 AI 도구를 사용하여 데이터 분석 애플리케이션을 구축하는 방법에 대한 단계별 가이드입니다. 특히 Cursor와 Pandas AI라는 두 가지 AI 도구에 초점을 맞출 것입니다.
AI 도구 1: Cursor
Cursor는 전체 코드베이스에 액세스할 수 있는 AI 코드 에디터입니다. Cursor의 채팅 인터페이스에 프롬프트를 입력하기만 하면, 디렉토리의 모든 파일에 액세스하고 코드를 자동으로 편집해 줍니다.
초보자이고 코드를 한 줄도 작성할 수 없더라도, 빈 코드 폴더로 시작하여 Cursor에게 무언가를 구축해 달라고 요청할 수 있습니다. AI 도구는 지시에 따라 요구 사항에 맞는 코드 파일을 생성합니다.
다음은 코드를 한 줄도 작성하지 않고 Cursor를 사용하여 엔드투엔드 데이터 분석 프로젝트를 구축하는 방법에 대한 가이드입니다.
1단계: Cursor 설치 및 설정
Cursor AI를 데이터 분석에 어떻게 사용할 수 있는지 살펴보겠습니다.
Cursor를 설치하려면 www.cursor.com으로 이동하여 OS와 호환되는 버전을 다운로드하고 설치 지침을 따르면 몇 초 만에 설정됩니다.
Cursor 인터페이스는 다음과 같습니다:
이 튜토리얼을 따라하려면 Kaggle의 Sentiment Analysis Dataset에서 `train.csv` 파일을 다운로드하세요.
그런 다음 "Sentiment Analysis Project"라는 폴더를 만들고 다운로드한 train.csv 파일을 그 안에 넣으세요.
마지막으로 `app.py`라는 빈 파일을 만드세요. 프로젝트 폴더는 다음과 같아야 합니다:
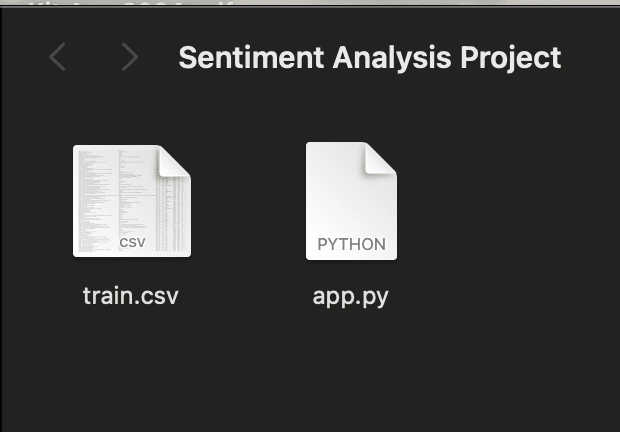
이것이 우리의 작업 디렉토리가 됩니다.
이제 File -> Open Folder로 이동하여 Cursor에서 이 폴더를 열어주세요.
화면 오른쪽에는 Cursor에 프롬프트를 입력할 수 있는 채팅 인터페이스가 있습니다. 여기서 몇 가지 선택 사항이 있는데, 드롭다운에서 "Agent"를 선택합니다.
이렇게 하면 Cursor가 코드베이스를 탐색하고 코드를 리팩토링하고 디버깅하는 AI 어시스턴트 역할을 합니다.
또한 Cursor와 함께 사용할 언어 모델(GPT-4o, Gemini-2.5-Pro 등)을 선택할 수 있습니다. 고급 코딩 기능으로 잘 알려진 모델인 Claude-4-Sonnet를 사용하는 것이 좋습니다.
2단계: Cursor에게 애플리케이션 구축 요청하기
이제 Cursor에 다음 프롬프트를 입력하여 코드베이스의 훈련 데이터셋을 사용하여 엔드투엔드 감정 분석 모델을 구축하도록 요청해 봅시다:
```
Create a sentiment analysis web app that:
- Uses a pre-trained DistilBERT model to analyze the sentiment of text (positive, negative, or neutral)
- Has a simple web interface where users can enter text and see results
- Shows the sentiment result with appropriate colors (green for positive, red for negative)
- Runs immediately without needing any training
Please connect all the files properly so that when I enter text and click analyze, it shows me the sentiment result right away.
```
이 프롬프트를 Cursor에 입력하면 감정 분석 애플리케이션을 구축하기 위한 코드 파일이 자동으로 생성됩니다.
3단계: 변경 사항 수락 및 명령 실행
Cursor가 새 파일을 만들고 코드를 생성함에 따라 AI 에이전트가 변경한 내용을 확인하기 위해 "Accept"를 클릭해야 합니다.
Cursor가 모든 코드를 작성한 후, 터미널에서 몇 가지 명령을 실행하라는 메시지가 표시될 수 있습니다. 이러한 명령을 실행하면 필요한 의존성을 설치하고 웹 애플리케이션을 실행할 수 있습니다.
"Run"을 클릭하면 Cursor가 이러한 명령을 실행합니다:
Cursor가 애플리케이션을 구축하면 다음 링크를 브라우저에 복사하여 붙여넣으라고 알려줍니다:

이 링크를 통해 다음과 같은 감정 분석 웹 애플리케이션에 접속할 수 있습니다:
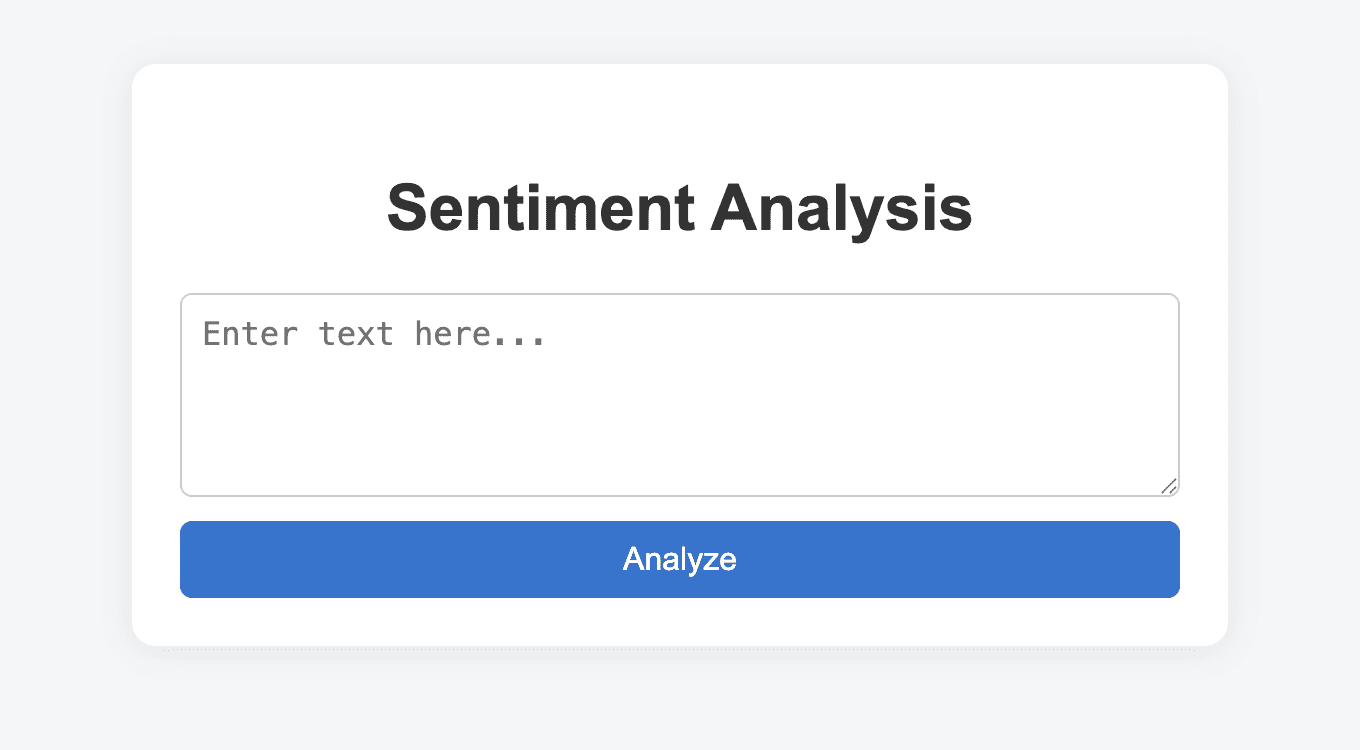
이것은 고용주가 상호작용할 수 있는 완전한 웹 애플리케이션입니다. 이 앱에 어떤 문장이든 붙여넣으면 감정을 예측하고 결과를 반환합니다.
Cursor와 같은 도구는 이 분야의 초보자이고 프로젝트를 제품화하고 싶을 때 특히 강력합니다.
대부분의 데이터 전문가들은 HTML 및 CSS와 같은 프론트엔드 프로그래밍 언어를 모르기 때문에 프로젝트를 대화형 애플리케이션으로 보여줄 수 없습니다.
우리의 코드는 종종 Kaggle 노트북에만 머무르며, 이는 똑같은 일을 하는 수백 명의 다른 지원자들보다 경쟁 우위를 제공하지 않습니다.
그러나 Cursor와 같은 도구는 경쟁에서 차별화될 수 있습니다. 아이디어를 현실로 바꾸고 지시한 내용을 정확히 코딩할 수 있도록 도와줍니다.
AI 도구 2: Pandas AI
Pandas AI를 사용하면 코드를 작성하지 않고도 Pandas 데이터프레임을 조작하고 분석할 수 있습니다.
일반 영어로 프롬프트를 입력하기만 하면 되며, 이는 데이터 전처리와 EDA 수행에 따르는 복잡성을 줄여줍니다.
아직 모르신다면, Pandas는 데이터를 분석하고 조작하는 데 사용할 수 있는 Python 라이브러리입니다.
데이터를 Pandas 데이터프레임이라고 하는 것으로 읽어들여 데이터에 대한 작업을 수행할 수 있습니다.
Pandas AI로 데이터 전처리, 조작 및 분석을 수행하는 방법의 예를 살펴보겠습니다.
이 데모에서는 Kaggle의 타이타닉 생존 예측 데이터셋을 사용하겠습니다(`train.csv` 파일 다운로드).
이 분석을 위해 Jupyter Notebook, Kaggle Notebook 또는 Google Colab과 같은 Python 노트북 환경을 사용하는 것이 좋습니다.
1단계: Pandas AI 설치 및 설정
노트북 환경이 준비되면 아래 명령을 입력하여 Pandas AI를 설치하세요:
```
!pip install pandasai
```
다음으로, 다음 코드 라인으로 타이타닉 데이터프레임을 로드합니다:
```python
import pandas as pd
traindata = pd.readcsv('/kaggle/input/titanic/train.csv')
```
이제 다음 라이브러리를 가져옵시다:
```python
import os
from pandasai import SmartDataframe
from pandasai.llm.openai import OpenAI
```
다음으로, 타이타닉 훈련 데이터셋을 분석할 Pandas AI 객체를 생성해야 합니다.
Pandas AI는 Pandas 데이터프레임을 대규모 언어 모델(LLM)에 연결하는 라이브러리입니다. Pandas AI를 사용하여 GPT-4o, Claude-3.5 및 기타 LLM에 연결할 수 있습니다.
기본적으로 Pandas AI는 Bamboo LLM이라는 언어 모델을 사용합니다. Pandas AI를 언어 모델에 연결하려면 이 웹사이트를 방문하여 API 키를 얻을 수 있습니다.
그런 다음 이 코드 블록에 API 키를 입력하여 Pandas AI 객체를 생성합니다:
```python
Set the PandasAI API key
By default, unless you choose a different LLM, it will use BambooLLM.
You can get your free API key by signing up at https://app.pandabi.ai
os.environ['PANDASAIAPIKEY'] = 'your-pandasai-api-key' # Replace with your actual key
Create SmartDataframe with default LLM (Bamboo)
smartdf = SmartDataframe(traindata)
```
개인적으로 Bamboo LLM API 키를 검색하는 데 몇 가지 문제가 있었습니다. 이로 인해 대신 OpenAI에서 API 키를 얻기로 결정했습니다. 그런 다음 이 분석에 GPT-4o 모델을 사용했습니다.
이 접근 방식의 한 가지 주의사항은 OpenAI의 API 키가 무료가 아니라는 것입니다. 이러한 모델을 사용하려면 OpenAI의 API 토큰을 구매해야 합니다.
이렇게 하려면 OpenAI 웹사이트로 이동하여 결제 페이지에서 토큰을 구매하세요. 그런 다음 "API 키" 페이지로 이동하여 API 키를 생성할 수 있습니다.
이제 OpenAI API 키가 있으므로 GPT-4o 모델을 Pandas AI에 연결하기 위해 이 코드 블록에 입력해야 합니다:
```python
Set your OpenAI API key
os.environ["OPENAIAPIKEY"] = "YOURAPIKEY"
Initialize OpenAI LLM
llm = OpenAI(apitoken=os.environ["OPENAIAPI_KEY"], model="gpt-4o")
config = {
"llm": llm,
"enable_cache": False,
"verbose": False,
"save_logs": True
}
Create SmartDataframe with explicit configuration
smartdf = SmartDataframe(traindata, config=config)
```
이제 이 Pandas AI 객체를 사용하여 타이타닉 데이터셋을 분석할 수 있습니다.
2단계: Pandas AI를 이용한 EDA 및 데이터 전처리
먼저 Pandas AI에게 이 데이터셋을 설명해 달라는 간단한 프롬프트로 시작해 보겠습니다:
```
smart_df.chat("Can you describe this dataset and provide a summary, format the output as a table.")
```
다음과 같이 데이터셋의 기본 통계 요약이 포함된 결과가 표시됩니다:
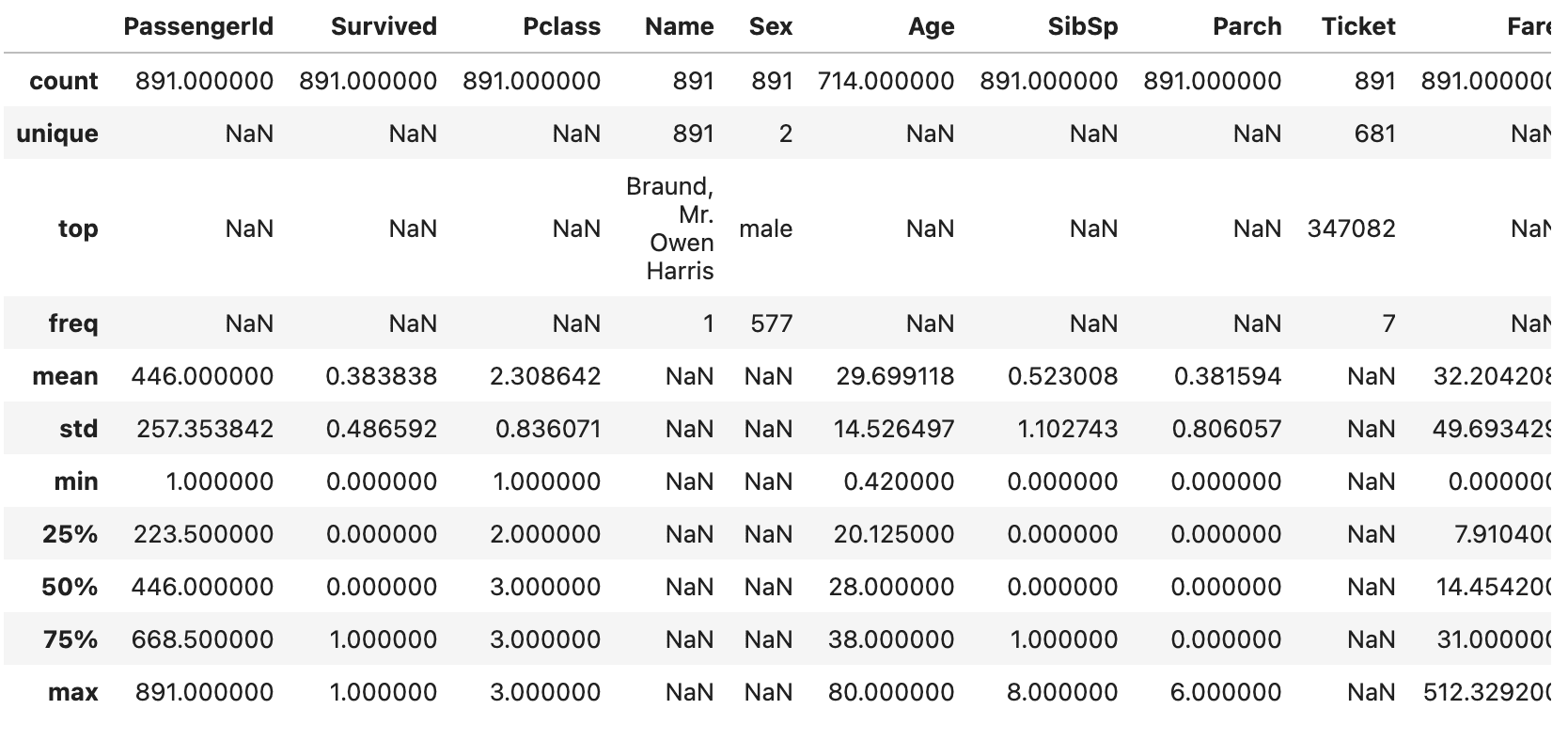
일반적으로 이런 요약을 얻기 위해 코드를 작성해야 합니다. 그러나 Pandas AI를 사용하면 프롬프트만 작성하면 됩니다.
이는 데이터를 분석하고 싶지만 Python 코드를 작성하는 방법을 모르는 초보자에게 많은 시간을 절약해 줄 것입니다.
다음으로, Pandas AI로 탐색적 데이터 분석을 수행해 보겠습니다:
타이타닉 데이터셋의 "Survived" 변수와 데이터셋의 다른 변수 간의 관계를 알려달라고 요청하겠습니다:
```
smart_df.chat("Are there correlations between Survived and the following variables: Age, Sex, Ticket Fare. Format this output as a table.")
```
위 프롬프트는 "Survived"와 데이터셋의 다른 변수 간의 상관 계수를 제공합니다.
다음으로, Pandas AI에게 이러한 변수 간의 관계를 시각화하도록 요청해 보겠습니다:
1. Survived와 Age
```
smart_df.chat("Can you visualize the relationship between the Survived and Age columns?")
```
위 프롬프트는 다음과 같은 히스토그램을 제공합니다:
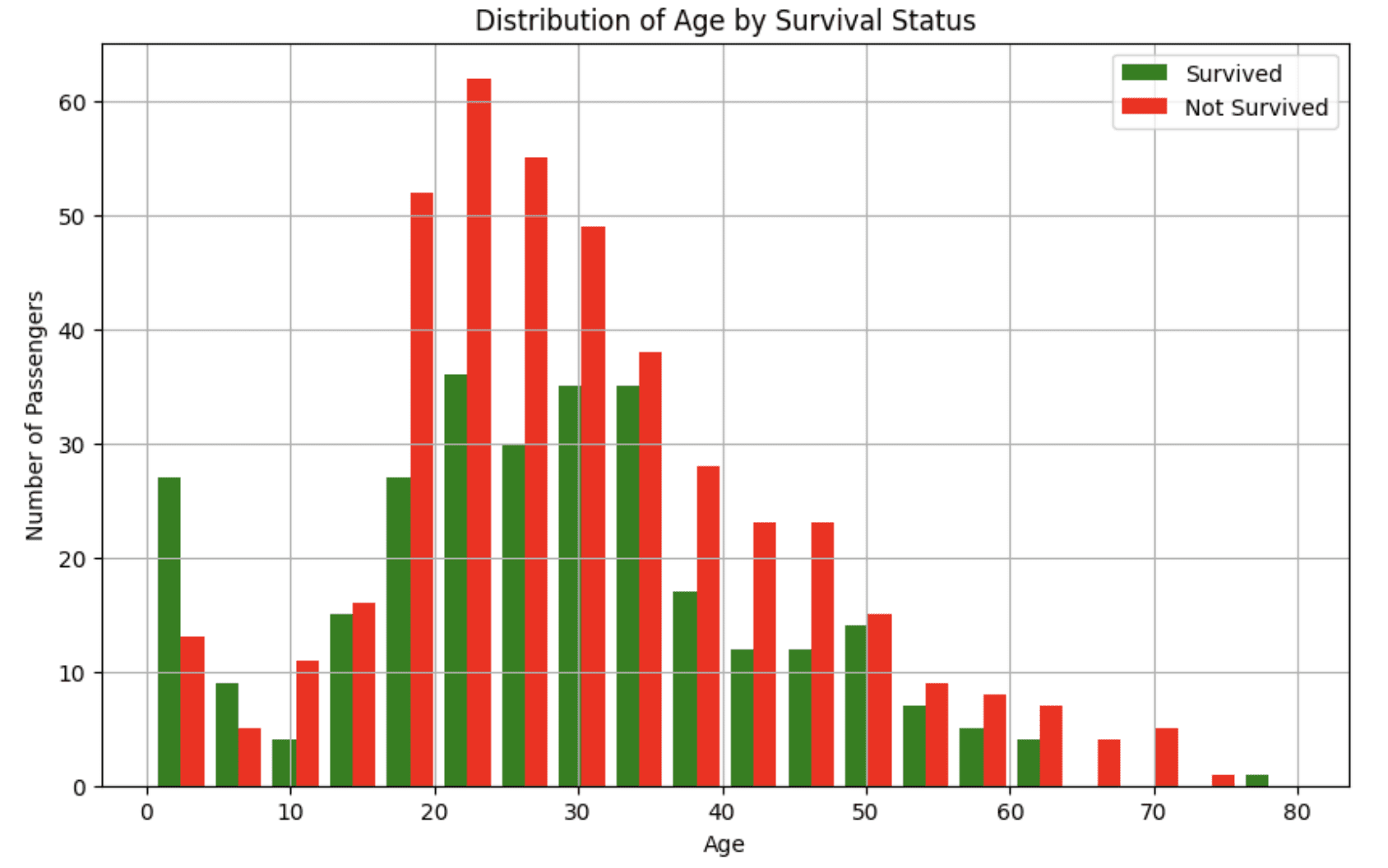
이 시각화는 젊은 승객이 사고에서 생존할 가능성이 더 높았다는 것을 알려줍니다.
2. Survived와 Gender
```
smart_df.chat("Can you visualize the relationship between the Survived and Sex")
```
"Survived"와 "Gender" 간의 관계를 보여주는 막대 차트가 생성됩니다.
3. Survived와 Fare
```
smart_df.chat("Can you visualize the relationship between the Survived and Fare")
```
위 프롬프트는 박스 플롯을 생성하여 더 높은 운임을 지불한 승객이 타이타닉 사고에서 생존할 가능성이 더 높았다는 것을 보여줍니다.
LLM은 비결정적이기 때문에 여러분이 얻는 출력은 제 것과 다를 수 있습니다. 그러나 여전히 데이터셋을 더 잘 이해하는 데 도움이 되는 응답을 받을 것입니다.
다음으로, 다음과 같은 프롬프트로 데이터 전처리를 수행할 수 있습니다:
프롬프트 예시 1
```
smart_df.chat("Analyze the quality of this dataset. Identify missing values, outliers, and potential data issues that would need to be addressed before we build a model to predict survival.")
```
프롬프트 예시 2
```
smart_df.chat("Let's drop the cabin column from the dataframe as it has too many missing values.")
```
프롬프트 예시 3
```
smart_df.chat("Let's impute the Age column with the median value.")
```
5분도 채 걸리지 않아 결측값 처리, 범주형 변수 인코딩, 새로운 특성 생성 등의 전처리 과정을 마쳤습니다. 이 모든 것이 많은 Python 코드를 작성하지 않고 이루어졌으며, 특히 프로그래밍을 처음 접하는 사람에게 도움이 됩니다.
AI 데이터 분석 학습: 다음 단계
제 의견으로는 Cursor와 Pandas AI와 같은 도구의 주요 장점은 프로그래밍 인터페이스 내에서 데이터를 분석하고 코드를 편집할 수 있다는 것입니다.
이는 프로그래밍 IDE에서 코드를 복사하여 ChatGPT와 같은 인터페이스에 붙여넣는 것보다 훨씬 낫습니다.
또한 코드베이스가 커질수록(예: 수천 줄의 코드와 10개 이상의 데이터셋이 있는 경우) 모든 맥락을 갖고 있고 이러한 코드 파일 간의 연결을 이해할 수 있는 통합 AI 도구를 가지는 것이 매우 유용합니다.
데이터 분석을 위해 AI를 배우고자 한다면, 다음과 같은 도구들도 유용할 것입니다:
- GitHub Copilot: 이 도구는 Cursor와 유사합니다. 프로그래밍 IDE 내에서 코드 제안을 생성하는 데 사용할 수 있으며, 상호작용할 수 있는 채팅 인터페이스도 있습니다.
- Microsoft Copilot in Excel: 이 AI 도구는 스프레드시트의 데이터를 자동으로 분석하는 데 도움을 줍니다.