Streamlit, Pandas, Plotly를 활용한 인터랙티브 데이터 앱 만들기

소개
Streamlit, Pandas, Plotly를 함께 사용하면 Python으로 인터랙티브한 웹 기반 데이터 대시보드를 쉽게 만들 수 있습니다. 이 세 라이브러리는 정적인 데이터셋을 반응형의 시각적으로 매력적인 애플리케이션으로 변환해줍니다. 웹 개발 배경 지식이 없어도 가능합니다.
시작하기 전에 중요한 구조적 차이점을 이해해야 합니다. matplotlib이나 seaborn 같은 라이브러리들은 Jupyter 노트북에서 직접 작동하는 반면, Streamlit은 명령줄에서 실행해야 하는 독립적인 웹 애플리케이션을 만듭니다. VS Code와 같은 텍스트 기반 IDE에서 코드를 작성하고 .py 파일로 저장한 다음 streamlit run filename.py를 사용하여 실행합니다. 이러한 노트북 환경에서 스크립트 기반 개발로의 전환은 데이터 애플리케이션 공유 및 배포에 새로운 가능성을 열어줍니다.
이 실습 튜토리얼에서는 두 가지 명확한 단계로 완전한 판매 대시보드를 구축하는 방법을 배웁니다. Streamlit과 Pandas만 사용하여 핵심 기능부터 시작한 다음, Plotly를 사용하여 인터랙티브한 시각화로 대시보드를 향상시킬 것입니다.
설정
필요한 패키지 설치:
```
pip install streamlit pandas plotly
```
프로젝트를 위한 새 폴더를 만들고 VS Code(또는 원하는 텍스트 에디터)에서 여세요.
1단계: Streamlit + Pandas 대시보드
먼저 Streamlit과 Pandas만 사용하여 기능적인 대시보드를 만들어 보겠습니다. 이는 Streamlit이 인터랙티브한 웹 인터페이스를 만들고 Pandas가 데이터 필터링을 처리하는 방법을 보여줍니다.
step1dashboardbasic.py 파일을 생성하세요:
```
import streamlit as st
import pandas as pd
import numpy as np
Page config
st.setpageconfig(page_title='Basic Sales Dashboard', layout='wide')
Generate sample data
np.random.seed(42)
df = pd.DataFrame({
'Date': pd.date_range('2024-01-01', periods=100),
'Sales': np.random.randint(500, 2000, size=100),
'Region': np.random.choice(['North', 'South', 'East', 'West'], size=100),
'Product': np.random.choice(['Product A', 'Product B', 'Product C'], size=100)
})
Sidebar filters
st.sidebar.title('Filters')
regions = st.sidebar.multiselect('Select Region', df['Region'].unique(), default=df['Region'].unique())
products = st.sidebar.multiselect('Select Product', df['Product'].unique(), default=df['Product'].unique())
Filter data
filtered_df = df[(df['Region'].isin(regions)) & (df['Product'].isin(products))]
Display metrics
col1, col2, col3 = st.columns(3)
col1.metric("Total Sales", f"${filtered_df['Sales'].sum():,}")
col2.metric("Average Sales", f"${filtered_df['Sales'].mean():.0f}")
col3.metric("Records", len(filtered_df))
Display filtered data
st.subheader("Filtered Data")
st.dataframe(filtered_df)
```
여기서 사용된 주요 Streamlit 메서드를 분석해 보겠습니다:
- st.setpageconfig() : 브라우저 탭 제목과 레이아웃을 구성합니다
- st.sidebar : 필터용 왼쪽 탐색 패널을 만듭니다
- st.multiselect() : 사용자 선택을 위한 드롭다운 메뉴를 생성합니다
- st.columns() : 나란히 배치된 레이아웃 섹션을 만듭니다
- st.metric() : 라벨이 있는 큰 숫자를 표시합니다
- st.dataframe() : 인터랙티브한 데이터 테이블을 렌더링합니다
이러한 메서드는 사용자 상호작용을 자동으로 처리하고 선택이 변경될 때 앱 업데이트를 트리거합니다.
터미널(또는 VS Code의 통합 터미널)에서 다음을 실행하세요:
```
streamlit run step1dashboardbasic.py
```
브라우저가 http://localhost:8501에서 인터랙티브 대시보드를 보여줄 것입니다.
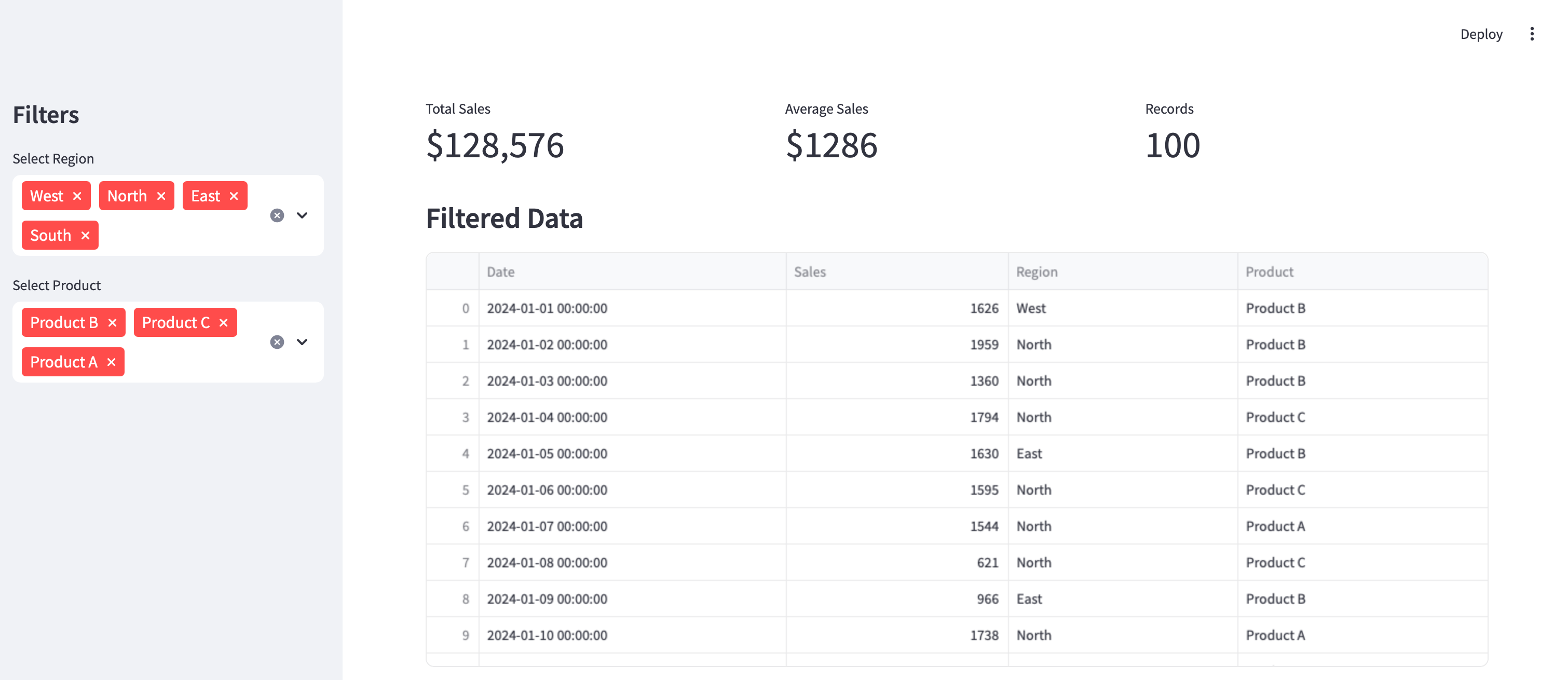
사이드바에서 필터를 변경해 보세요 - 지표와 데이터 테이블이 자동으로 업데이트되는 것을 볼 수 있습니다! 이는 Streamlit의 반응형 특성과 Pandas의 데이터 조작 기능이 결합된 결과입니다.
2단계: Plotly로 인터랙티브 시각화 추가하기
이제 Plotly의 인터랙티브 차트를 추가하여 대시보드를 향상시켜 보겠습니다. 이것은 세 라이브러리가 어떻게 원활하게 함께 작동하는지 보여줍니다. 새 파일을 만들고 step2dashboardplotly.py라고 이름 붙이세요:
```
import streamlit as st
import pandas as pd
import plotly.express as px
import numpy as np
Page config
st.setpageconfig(page_title='Sales Dashboard with Plotly', layout='wide')
Generate data
np.random.seed(42)
df = pd.DataFrame({
'Date': pd.date_range('2024-01-01', periods=100),
'Sales': np.random.randint(500, 2000, size=100),
'Region': np.random.choice(['North', 'South', 'East', 'West'], size=100),
'Product': np.random.choice(['Product A', 'Product B', 'Product C'], size=100)
})
Sidebar filters
st.sidebar.title('Filters')
regions = st.sidebar.multiselect('Select Region', df['Region'].unique(), default=df['Region'].unique())
products = st.sidebar.multiselect('Select Product', df['Product'].unique(), default=df['Product'].unique())
Filter data
filtered_df = df[(df['Region'].isin(regions)) & (df['Product'].isin(products))]
Metrics
col1, col2, col3 = st.columns(3)
col1.metric("Total Sales", f"${filtered_df['Sales'].sum():,}")
col2.metric("Average Sales", f"${filtered_df['Sales'].mean():.0f}")
col3.metric("Records", len(filtered_df))
Charts
col1, col2 = st.columns(2)
with col1:
figline = px.line(filtereddf, x='Date', y='Sales', color='Region', title='Sales Over Time')
st.plotlychart(figline, usecontainerwidth=True)
with col2:
regionsales = filtereddf.groupby('Region')['Sales'].sum().reset_index()
figbar = px.bar(regionsales, x='Region', y='Sales', title='Total Sales by Region')
st.plotlychart(figbar, usecontainerwidth=True)
Data table
st.subheader("Filtered Data")
st.dataframe(filtered_df)
```
터미널(또는 VS Code의 통합 터미널)에서 다음을 실행하세요:
```
streamlit run step2dashboardplotly.py
```
이제 완전한 인터랙티브 대시보드가 생겼습니다!
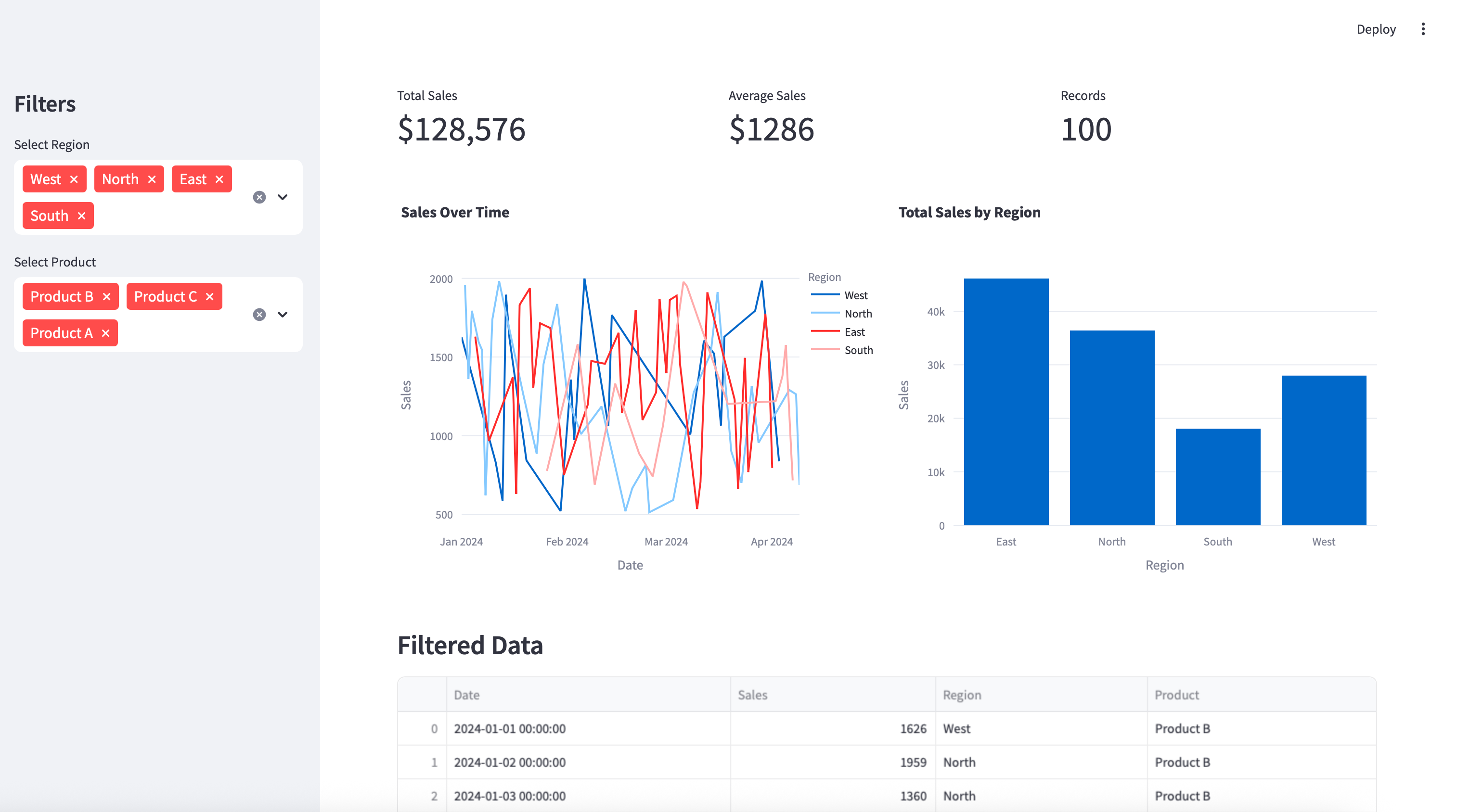
Plotly 차트는 완전히 인터랙티브합니다 - 데이터 포인트 위로 마우스를 올리고, 특정 시간 기간을 확대하고, 심지어 범례 항목을 클릭하여 데이터 시리즈를 표시/숨길 수도 있습니다.
세 라이브러리가 함께 작동하는 방식
이 조합은 각 라이브러리가 자신이 가장 잘하는 일을 처리하기 때문에 강력합니다:
Pandas는 모든 데이터 작업을 관리합니다:
- 데이터셋 생성 및 로드
- 사용자 선택에 따른 데이터 필터링
- 시각화를 위한 데이터 집계
- 데이터 변환 처리
Streamlit은 웹 인터페이스를 제공합니다:
- 인터랙티브한 위젯(멀티셀렉트, 슬라이더 등) 생성
- 사용자가 위젯과 상호작용할 때 전체 앱을 자동으로 재실행
- 반응형 프로그래밍 모델 처리
- 열과 컨테이너로 레이아웃 관리
Plotly는 풍부하고 인터랙티브한 시각화를 만듭니다:
- 사용자가 마우스 호버, 확대/축소 및 탐색할 수 있는 차트
- 최소한의 코드로 전문적인 그래프 생성
주요 개발 워크플로우
개발 프로세스는 간단한 패턴을 따릅니다. VS Code나 텍스트 에디터에서 코드를 작성하고 .py 파일로 저장하는 것부터 시작하세요. 다음으로, 터미널에서 streamlit run filename.py를 사용하여 애플리케이션을 실행하면 브라우저에서 http://localhost:8501에 대시보드가 열립니다. 코드를 편집하고 저장하면 Streamlit이 자동으로 변경 사항을 감지하고 애플리케이션을 다시 실행할 것을 제안합니다. 대시보드에 만족하면 Streamlit Community Cloud를 사용하여 배포하고 다른 사람들과 공유할 수 있습니다.
다음 단계
다음과 같은 향상 기능을 시도해 보세요:
실제 데이터 추가:
```
Replace sample data with CSV upload
uploadedfile = st.sidebar.fileuploader("Upload CSV", type="csv")
if uploaded_file:
df = pd.readcsv(uploadedfile)
```
실제 데이터셋은 데이터 구조에 특화된 전처리 단계가 필요하다는 점을 명심하세요. 열 이름을 조정하고, 누락된 값을 처리하고, 실제 데이터 필드에 맞게 필터 옵션을 수정해야 합니다. 샘플 코드는 템플릿을 제공하지만, 각 데이터셋은 정리 및 준비를 위한 고유한 요구 사항이 있을 것입니다.
더 많은 차트 유형:
```
Pie chart for product distribution
figpie = px.pie(filtereddf, values='Sales', names='Product', title='Sales by Product')
st.plotlychart(figpie)
```
대시보드 배포하기
대시보드가 로컬에서 작동하면, Streamlit Community Cloud를 통해 다른 사람들과 공유하는 것이 간단합니다. 먼저 코드를 공개 GitHub 저장소에 푸시하고, 의존성(streamlit, pandas, plotly)을 나열하는 requirements.txt 파일을 포함해야 합니다. 그런 다음 https://streamlit.io/cloud를 방문하여 GitHub 계정으로 로그인하고 저장소를 선택하세요. Streamlit이 자동으로 앱을 빌드하고 배포하여 누구나 접근할 수 있는 공개 URL을 제공합니다. 무료 티어는 여러 앱을 지원하고 적절한 트래픽 부하를 처리하므로 동료들과 대시보드를 공유하거나 포트폴리오에서 작업을 선보이기에 완벽합니다.
결론
Streamlit, Pandas, Plotly의 조합은 데이터 분석을 정적 보고서에서 인터랙티브한 웹 애플리케이션으로 변환합니다. 단 두 개의 Python 파일과 몇 가지 메서드만으로도 고가의 비즈니스 인텔리전스 도구에 버금가는 완전한 대시보드를 구축했습니다.
이 튜토리얼은 데이터 과학자들이 자신의 작업을 공유하는 방식의 중요한 변화를 보여줍니다. 정적 차트를 보내거나 동료들이 Jupyter 노트북을 실행하도록 요구하는 대신, 이제 누구나 브라우저를 통해 사용할 수 있는 웹 애플리케이션을 만들 수 있습니다. 노트북 기반 분석에서 스크립트 기반 애플리케이션으로의 전환은 데이터 전문가들이 자신의 통찰력을 더 접근하기 쉽고 영향력 있게 만들 수 있는 새로운 기회를 제공합니다.
이러한 도구로 계속 구축하면서, 인터랙티브한 대시보드가 조직 내에서 전통적인 보고를 어떻게 대체할 수 있는지 고려해 보세요. 여기서 배운 동일한 원칙은 실제 데이터셋, 복잡한 계산 및 정교한 시각화를 처리하도록 확장됩니다. 임원용 대시보드, 탐색적 데이터 도구 또는 고객 대면 애플리케이션을 만드는 것이든, 이 세 라이브러리 조합은 전문적인 데이터 애플리케이션을 위한 견고한 기반을 제공합니다.