파이썬으로 50줄 이하의 견고한 데이터 정제 및 검증 파이프라인 구축하기

데이터 정제 파이프라인이 필요한 이유
데이터는 항상 깔끔하지 않습니다. API에서 정보를 가져오거나 실제 데이터셋을 분석할 때 중복, 누락된 값, 유효하지 않은 항목을 마주치게 됩니다. 매번 같은 정제 코드를 작성하는 대신, 잘 설계된 파이프라인은 시간을 절약하고 데이터 과학 프로젝트 전반에 걸쳐 일관성을 보장합니다.
이 글에서는 일반적인 데이터 품질 문제를 처리하고 수정된 내용에 대한 상세한 피드백을 제공하는 재사용 가능한 데이터 정제 및 검증 파이프라인을 구축할 것입니다.
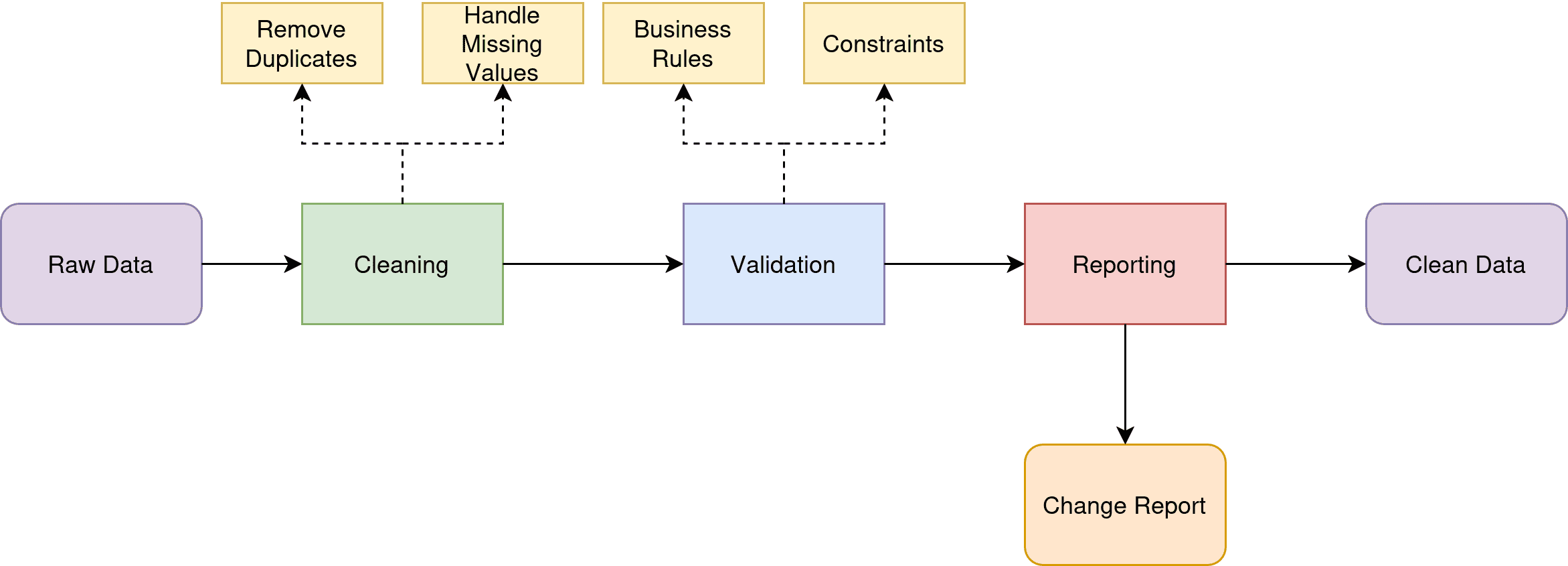
우리의 파이프라인은 세 가지 핵심 책임을 다룹니다:
- 정제: 중복 제거 및 누락된 값 처리 (더 많은 정제 단계 추가 가능)
- 검증: 데이터가 비즈니스 규칙과 제약 조건을 충족하는지 확인
개발 환경 설정
최신 버전의 Python을 사용하고 있는지 확인하세요. 로컬에서 사용하는 경우 가상 환경을 만들고 필요한 패키지를 설치하세요:
- pandas
- Pydantic
Google Colab이나 유사한 노트북 환경을 사용해도 됩니다.
검증 스키마 정의
데이터를 검증하기 전에 "유효한" 데이터의 조건을 정의해야 합니다. 데이터 유형을 검증하기 위해 타입 힌트를 사용하는 Python 라이브러리인 Pydantic을 사용하겠습니다.
```python
class DataValidator(BaseModel):
name: str
age: Optional[int] = None
email: Optional[str] = None
salary: Optional[float] = None
@field_validator('age')
@classmethod
def validate_age(cls, v):
if v is not None and (v < 0 or v > 100):
raise ValueError('Age must be between 0 and 100')
return v
@field_validator('email')
@classmethod
def validate_email(cls, v):
if v and '@' not in v:
raise ValueError('Invalid email format')
return v
```
이 스키마는 Pydantic의 문법을 사용해 예상되는 데이터를 모델링합니다. `@field_validator` 데코레이터를 사용하려면 `@classmethod` 데코레이터가 필요합니다. 검증 로직은 나이가 합리적인 범위 내에 있고 이메일에 '@' 기호가 포함되어 있는지 확인합니다.
파이프라인 클래스 구축
메인 파이프라인 클래스는 모든 정제 및 검증 로직을 캡슐화합니다:
```python
class DataPipeline:
def init(self):
self.cleaningstats = {'duplicatesremoved': 0, 'nullshandled': 0, 'validationerrors': 0}
```
생성자는 처리 과정 동안 발생한 변경 사항을 추적하기 위한 통계 사전을 초기화합니다. 이는 데이터 품질을 자세히 살펴보고 시간이 지남에 따라 적용된 정제 단계를 추적하는 데 도움이 됩니다.
데이터 정제 로직 작성
누락된 값과 중복 레코드와 같은 일반적인 데이터 품질 문제를 처리하기 위해 `clean_data` 메서드를 추가합니다:
```python
def clean_data(self, df: pd.DataFrame) -> pd.DataFrame:
initial_rows = len(df)
# Remove duplicates
df = df.drop_duplicates()
self.cleaningstats['duplicatesremoved'] = initial_rows - len(df)
# Handle missing values
numericcolumns = df.selectdtypes(include=[np.number]).columns
df[numericcolumns] = df[numericcolumns].fillna(df[numeric_columns].median())
stringcolumns = df.selectdtypes(include=['object']).columns
df[stringcolumns] = df[stringcolumns].fillna('Unknown')
```
이 접근 방식은 다양한 데이터 유형을 처리하는 데 스마트합니다. 수치형 누락 값은 중앙값으로 채워지고(이상치에 대해 평균보다 더 견고함), 텍스트 열은 자리 표시자 값을 받습니다. 중복 제거는 중앙값 계산이 왜곡되지 않도록 먼저 발생합니다.
오류 추적으로 검증 추가
검증 단계는 각 행을 개별적으로 처리하여 유효한 데이터와 상세한 오류 정보를 모두 수집합니다:
```python
def validate_data(self, df: pd.DataFrame) -> pd.DataFrame:
valid_rows = []
errors = []
for idx, row in df.iterrows():
try:
validatedrow = DataValidator(row.todict())
validrows.append(validatedrow.model_dump())
except ValidationError as e:
errors.append({'row': idx, 'errors': str(e)})
self.cleaningstats['validationerrors'] = len(errors)
return pd.DataFrame(valid_rows), errors
```
이 행별 접근 방식은 하나의 잘못된 레코드가 전체 파이프라인을 중단시키지 않도록 합니다. 유효한 행은 계속 처리되는 반면 오류는 검토를 위해 캡처됩니다. 이는 처리 가능한 것을 처리하면서 문제를 표시해야 하는 프로덕션 환경에서 중요합니다.
파이프라인 조정
`process` 메서드는 모든 것을 하나로 묶습니다:
```python
def process(self, df: pd.DataFrame) -> Dict[str, Any]:
cleaneddf = self.cleandata(df.copy())
validateddf, validationerrors = self.validatedata(cleaneddf)
return {
'cleaneddata': validateddf,
'validationerrors': validationerrors,
'stats': self.cleaning_stats
}
```
반환 값은 정제된 데이터, 검증 오류 및 처리 통계를 포함하는 포괄적인 보고서입니다.
모든 것을 한데 모으기
다음은 실제로 파이프라인을 사용하는 방법입니다:
```python
Create sample messy data
sample_data = pd.DataFrame({
'name': ['Tara Jamison', 'Jane Smith', 'Lucy Lee', None, 'Clara Clark','Jane Smith'],
'age': [25, -5, 25, 35, 150,-5],
'email': ['taraj@email.com', 'invalid-email', 'lucy@email.com', 'jane@email.com', 'clara@email.com','invalid-email'],
'salary': [50000, 60000, 50000, None, 75000,60000]
})
pipeline = DataPipeline()
result = pipeline.process(sample_data)
```
파이프라인은 자동으로 중복 레코드를 제거하고, 누락된 이름을 'Unknown'으로 채우고, 누락된 급여를 중앙값으로 채우며, 음수 나이와 유효하지 않은 이메일에 대한 검증 오류를 표시합니다.
파이프라인 확장
이 파이프라인은 확장할 수 있는 기반을 제공합니다. 특정 요구 사항에 맞게 다음과 같은 개선 사항을 고려해 보세요:
맞춤형 정제 규칙: 전화번호나 주소 표준화와 같은 도메인별 정제를 위한 메서드 추가.
구성 가능한 검증: 같은 파이프라인이 다른 데이터 유형을 처리할 수 있도록 Pydantic 스키마를 구성 가능하게 만듭니다.
고급 오류 처리: 일시적인 오류에 대한 재시도 로직이나 일반적인 실수에 대한 자동 수정 구현.
성능 최적화: 대규모 데이터셋의 경우 벡터화된 작업이나 병렬 처리 사용을 고려하세요.
마무리
데이터 파이프라인은 단순히 개별 데이터셋을 정제하는 것이 아닙니다. 신뢰할 수 있고 유지 관리 가능한 시스템을 구축하는 것입니다.
이 파이프라인 접근 방식은 프로젝트 전반에 걸쳐 일관성을 보장하고 요구 사항이 변경됨에 따라 비즈니스 규칙을 쉽게 조정할 수 있게 합니다. 이 기본 파이프라인으로 시작한 다음 특정 요구 사항에 맞게 사용자 지정하세요.
중요한 것은 일상적인 작업을 처리하는 신뢰할 수 있고 재사용 가능한 시스템을 갖추어 깨끗한 데이터에서 통찰력을 추출하는 데 집중할 수 있도록 하는 것입니다. 즐거운 데이터 정제가 되길 바랍니다!